How does the Search Engine (Google) Work to Rank the Content?
Search engine (Google) handles billions of queries, every day about all kinds of issues, events, solutions, and the list goes on and on.
Since there are so many searches happing in the search engine, it’s definitely an opportunity to flourish one’s business online.
Get more customers, add value to your business, attain goals in a defined time frame, increase sales and revenue, and become a thought Leader in your industry, name it SEO can help you achieve it.
But wait, before jumping into Google to grow your business, you would want to know, how search engines like, Google works.
As you keep on reading this article you will know the working process of the search engine to rank the content.
Let’s begin with an example,
Suppose, you want to buy a laptop and you made a search on Google. You’ll get thousands or millions of relevant results which you can rely on. But let’s go a bit deeper to understand.
Since Google got introduced to the world, Google has been tracking every happening on the internet to create an Index. An index is a library where Google goes hunting for the webpages whenever there is a search.
So when you search for a laptop in Google, you’ll get a lot of search results including the brand of laptop, latest models, price, images of laptops, and many more.
When you want to buy a laptop just clicking through random links won’t work. This is when Google ranking comes into play to understand the intent of the search.
Google crawls through the index, assembles possible webpages for the word “Laptop” and then displays them on the screen as a result.
But the question still remains, how does Google decide which page to display in SERPs and which pages to rank?
There are more than 200 ranking factors that Google takes into account to rank the content. Keywords, backlinks, and search location are a few of the major factors to rank the content.
When you make a search for a laptop from Nepal, you’ll get search results based on your location which includes, the cost of a laptop in Nepalese currency and the store where you can buy a laptop, with regard to all the ranking factors.
Moreover, the Google algorithm is getting better at scanning all the spam and delivering reliable search results.
So when you search for a laptop in Google’s search box, you won’t get a webpage with the keyword “laptop” stuff in it. Rather, you’ll get results with you can trust and take your further decision.
This is a brief scenario. Now, let’s go into detail to understand the 3-steps that search engine takes to rank content.
Search Engine: Crawl, Index, and Rank
The aim of a search engine is to present relevant and high-quality content to the searchers.
From the above example, you might have got a simple idea about the working mechanism of the search engine. Now let’s talk about it more specifically.
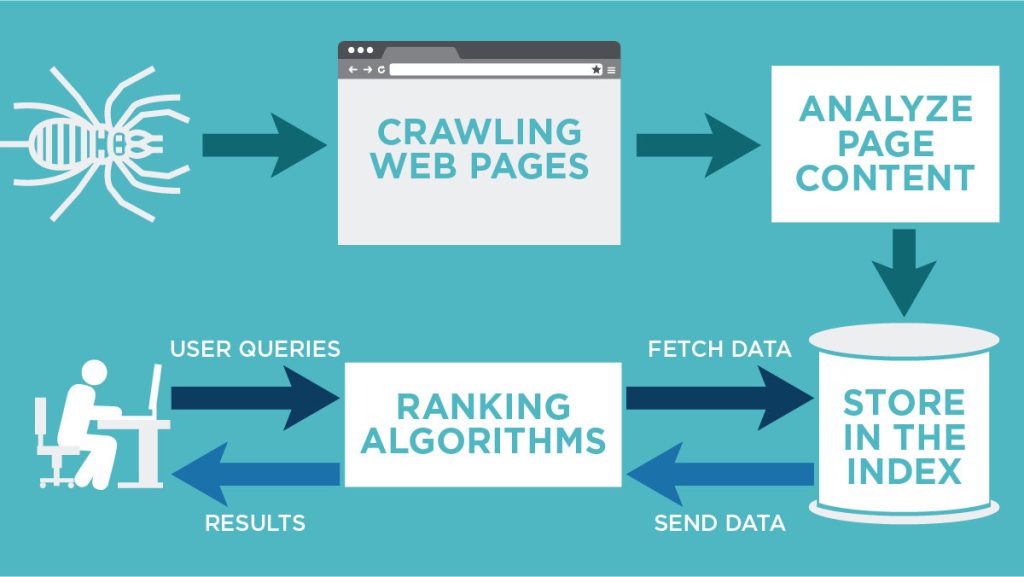
Crawl
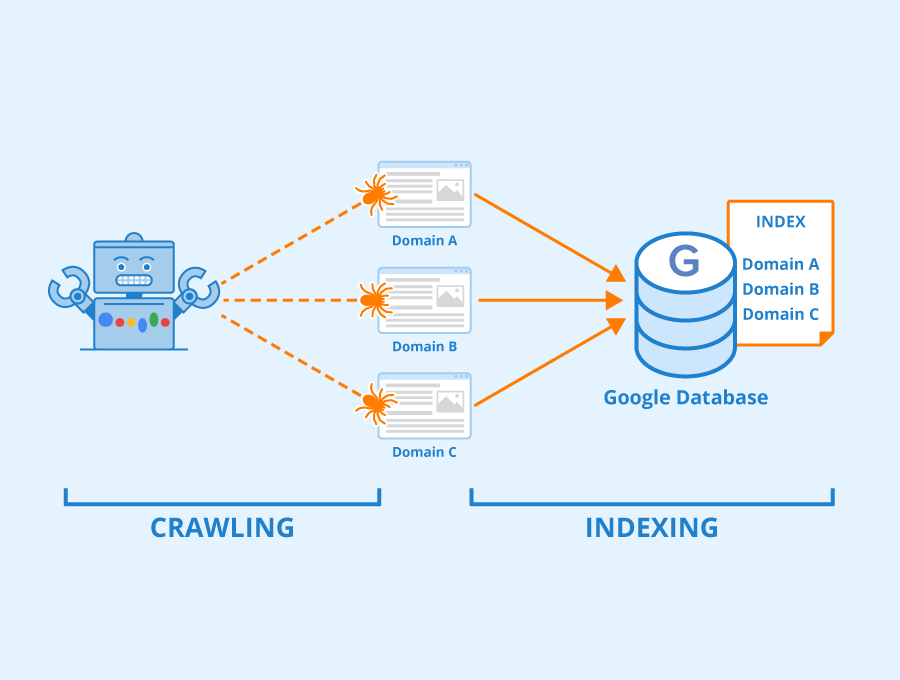
Crawling is how search engines like Google discover the webpage.
Google bots start by surfing through the web pages and then following the links on those web pages to find other websites. By moving from one link to another link it discovers the content and adds those content to the index called Caffeine.
Caffeine is the database to store discovered URLs and retrieved them whenever there is a relevant search. But, does Google crawls through every website and webpage on the internet?
Google’s budget helps Google to crawl each domain. Somehow, your page rank determines the crawl budget for your website. Google has a certain amount of resources to crawl, so Google has to be a bit selective to prioritize websites and webpage to get quality information as possible.
Is it possible to control Google crawler?
Yes. Controlling or blocking the bot from crawling is possible
If you want a bot to crawl through your website you need to implement the following tips:
- Let the crawler move through your website easily by defining the logical architect of your website that flows from domain to category to subcategory
- Use internal links so that crawler can move between the pages
- Create an XML sitemap (a file that lists the URLs for the website) to tell the crawler which page to crawl. There are plugins and tools like Google XML sitemaps to help generate and update the sitemap when you publish new content.
Additionally, you can block bots from finding a certain portion of your website and stop them from storing it on their index.
People do this to stop Google to find an old URL with thin content, a special promo code page, a test page, and so on. You can have control over what Google bots crawl and store from your website.
In order to control the crawling, you can use robot.txt to block bots from crawling through the website. You can also use rel=”nofollow” tag on individual links, it just affects that particular link, not the entire website.
Blocking the bot to a certain section of your website will not affect the ranking, it will allow you to allocate the crawl budget to an important webpage.
Index
Once the crawler discovered your page, the next step is to index the webpage. The bot categorizes the content which includes, images, keywords, CSS, and HTML.
This help search engine understands what’s in the content and assist to make a decision about which webpage to display when there is a search.
Additionally, you should also keep a close eye on the indexing of your website. For this, you can use Index status to check the bot indexing manner.
Index Status
Google webmaster has a tool called index status that allows you to know how Google is crawling and indexing your website. Moreover, you may learn how many pages Google has indexed as well.
Index status is a graph that shows how Google is responding to your webpage. You will notice an increase in the pages indexed when you regularly add material to your website. And if you see a drop in page indexed then this indicates that the crawler is finding difficulty in discovering the page and indexing it. The search engine is not able to correctly access your website.
Removed page from Index
Major reasons why URLs might be removed from the index:
- URL might have a “not found” error (4XX) or server error (5XX). This can happen if the page was removed and 301 redirects were not set up. 404 redirects might have been used to remove the page from the index
- The URL has a “noindex” meta tag. This can be done to omit the webpage from the index
- URL has been penalized for violating the search engine’s Webmaster Guideline
- URL has been blocked from crawling by adding a password
Rank
The final step is ranking. The ranking is the process, by which Google decides which content to display in SERPs. In other words, ranking is the ordering of the search result on the base of most to least relevant to the search query.
Google finds the relevant webpage to the search query in the index and displays it in the users’ screen accordingly. The algorithm has a number of factors to determine the quality of the webpage to index and rank it.
Major ranking factors
Backlinks
Backlinks are the links that direct people to your website from other websites. This is how you can impact the flow of traffic to your website and improve its position in the search engine. The best practice for earning backlinks is by posting guest blogs.
Keywords
Keywords are one of the important factors in how search engine defines the relevancy of the content. It signals Google that your webpage is relevant to the search query. But ensure that you’re not stuffing keywords and try making your content as reader-friendly as possible.
Mobile-friendly
In order to make the internet more accessible to consumers and to give mobile-friendly websites priority, Google modified its algorithm in 2015.
Relevancy
If you want your content to appear in SERPs, ensure that your content matches your audiences’ queries. This means that before publishing your material, be sure that your audience will find it valuable. If the content doesn’t answer the question of your audience then there is no use in publishing that content.
Domain authority
The domain authority defines website ranking in SERPs. Domain authority has a ranging score from one to a hundred. The highest-scoring website has a better probability of being ranked.
In order to give the best search results to users, Google has gone through many minor and major changes. The only reason for the changes is to display accurate and relevant results to the search queries. So, make sure that your content is user-friendly as well.
Final Thought
Once you have an idea of how a search engine works, you can develop your website that can crawl, index, and rank. . Make sure, your webpage serves your audience, and search engines find it relevant enough to display in SERPs. If you’re able to work with Google, your business can succeed in the online market.